Torben Peters, M. Sc.
Erstbetreuer: M. Sester; Co-Betreuer: C. Brenner
Many state of the art solutions in the fields of artificial intelligence are based on deep learning. In autonomous driving, deep learning is used i.a. for motion planning, object classification and detection or even end-to-end learning. In classical supervised learning such a network is trained with data of a specific domain for the given task. However if one domain intersects with another domain the knowledge can be transferred to another task. This procedure is therefore called transfer learning. Autonomous cars are often using different sensors in order to solve related problems. In this project we want to fuse different sensor information in order to minimize the need for data annotation. The Problem state is to map and control the information flow between different domains while preserving the quality of the data and their labels.
For this we investigate machine learning in large-scale 2D image- and 3D point cloud-data. We have created several datasets by merging image and point cloud data from our measurement campaigns (mapathons). By transferring knowledge between the two domains, we are able to train deep neural networks to solve new tasks in a semi and unsupervised fashion:
Semi Supervised Semantic Segmentation in 2D and 3D:
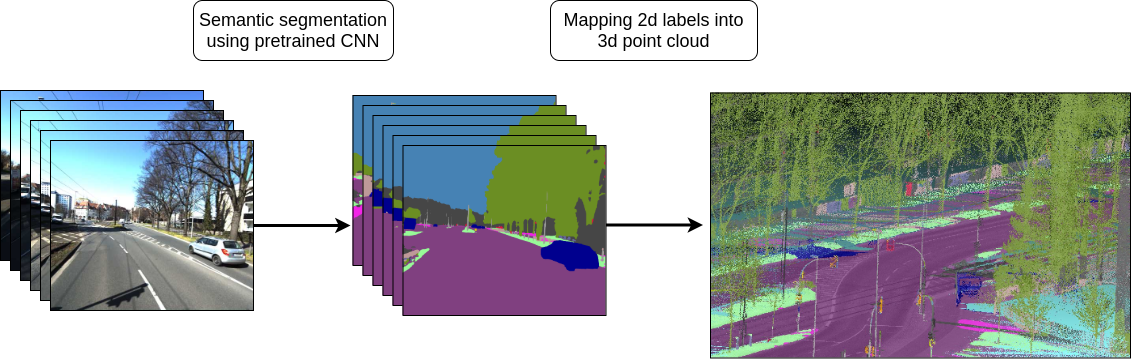
We have developed a method which allows us to annotate very large amounts of 3D data by transferring knowledge from the camera to the laser scanner domain. We do this by exploiting the geometric correspondence between lasersanner and camera in a calibrated system. As this procedure introduces label noise, we created features and methods to detect erroneous labels and to recover correct labels. In addition, we have developed a method for real-time semantic segmentation in 3D using a deep convolutional neural network (DCNN) which has been trained on the dataset. The following example shows an example of a semantic segmented point cloud by our DCNN which was trained entirely semi-supervised.

Secondly, by enforcing predictions to be consistent for the same object in space we created a procedure to adapt a pretrained 2D network to our camera sensors and increase the prediction quality in a semi-supervised way. This is enabled by projecting 3D object points into multi-view 2D images. Since every 3D object point is usually mapped to a number of 2D images, each of which undergoes a pixelwise classification using the pretrained DCNN, we obtain a number of predictions (labels) for the same object point. This makes it possible to detect and correct outlier predictions. Ultimately, we retrain the DCNN on the corrected dataset in order to adapt the network to the new input data. The following example shows that we were able to improve the predictions significantly after retraining the network.

Self-Supervised Completion in 2D and 3D:
In the same way that we have used cross-domain mapping for semantic segmentation, we show that we are able to estimate new data in a fully self-supervised way.
We show that we are able to predict new photorealistic looking images from 3D data only. Since the data was recorded over a whole year, we are able to parameterize the date so that we can predict the appearance for different seasons. In the following example, one can see how a 2D prediction is made for the summer and winter seasons, based on the same input 3D point cloud.

Our most recent work is currently being reviewed. Here we introduce a framework that is able to learn how to complete occluded 3D objects in a fully self-supervised way. For this purpose, we have used the labeled point clouds to automatically extract and instantiate objects. In this way, we have created a data set of almost 9,000 3D car scans. Since the cars are heavily occluded, we show that we can learn how to complete them in a self-supervised way by aggregating local shape information across the entire data set. The following example shows occluded 3D scans of cars from the KITTI dataset (red) and our prediction of a completed car (green).

Appelstraße 9A
30167 Hannover



